クローリングとは?活用方法やスクレイピングとの違い、メリット・デメリットを解説!

Webサイトを運営している方やWebマーケティングの勉強をされている方にとって、「クローリング」は見覚えのある言葉だと思います。この記事では、クローリングとスクレイピングの違いに加え、「自身がクローリングをする場合」と「検索エンジンなどにWebサイトをクローリングされる場合」の特徴を解説しています。ぜひともご確認ください。
-
Contents

クローリングとは?
クローリングとは、クローラーというプログラムがリンクをめぐってWebサイトを巡回し、Webページにある情報を複製・保存することです。英語の【crawl|はって行く、クロールで泳ぐ、のろのろ進む】が語源となり、クローラーがWeb上の情報をゆっくりと、収集していくイメージを持つとわかりやすいかと思います。
-
スクレイピングとの違い
Web上の情報収集プログラムとしては、クローリングの他に「スクレイピング」という言葉をご存知の方もいらっしゃると思います。スクレイピングもWebサイトなどを巡回し情報を収集しますが、情報収集の目的や焦点が異なります。
スクレイピングは英語の【scrape|こすり落とす、削り取る、(ひっかいて)掘る】が語源となり、必要な情報のみを抽出することを指します。具体的には、WebサイトのHTMLから見出し、タイトル、指定した言葉などの情報を集めます。クローリングがWebページ全域の情報収集を目的とているのに対し、スクレイピングは余分な情報を削ぎ落とし、必要なものだけを集めているイメージです。
しかし、一般的にクローリングとスクレイピングは上述したように区別されますが、厳密な定義などはありません。そのため、企業や現場によっては、Web上などからの情報収集をクローリングあるいはスクレイピングと称する場合もあるので注意しましょう。(※本記事では、クローリングに統一して説明をしていきます。)
-
クローリングが重要と言われる理由
Webサイトなどを作成する立場の視点となりますが、クローリング対策を採ることが重要だと言われています。なぜなら、検索エンジンで圧倒的なシェアを誇るGoogleの「GoogleBot」をはじめ、各検索エンジンはクローラー(クローリングをするプログラム)でWeb上の情報を集め、検索エンジンで利用するデータベースにWebサイトの情報を登録しているからです。
そのため、GoogleBotなどのクローラーにWebサイトなどを認識してもらわないと、作成したWebサイトが検索結果に表示されません。(Yahoo!JAPANなどの他の検索エンジンでも同様です。)
検索エンジンでの検索が一般化した現代では、作成したWebサイトが検索上位に表示されることでビジネスチャンスにつながります。そのため、Webサイトなどの訪問者数を増やすためにも、クローリング対策が重要だといわれています。
-
クローリングのメリット
クローリングのメリットを2つお伝えします。
-
大量のデータを収集できる
クローリングを利用すると大量のデータを収集できるため、ビッグデータ解析をはじめとするデータサイエンス業務などに活かすことができます。また、データ解析で導き出した情報は商品やサービス、マーケティングなどのビジネス展開や、研究機関での資料としても利用できます。
-
業務効率の向上を見込める
クローリングは、システムを開発すれば自動でデータ収集をしてくれます。そのため、業務工数の削減につながり効率的な作業ができるようになるでしょう。また、人力では不可能な量の情報収集ができるため、データ解析に利用する情報の母数が増え、より正確なデータの傾向を調べることができます。さらに、プログラムを利用しての情報収集となるため、ヒューマンエラーの削減にもつながります。
-
クローリングの注意点
情報収集において多くのメリットがあるクローリングですが、クローリングをおこなう際には注意をしなければいけません。ここでは2つをピックアップしてお伝えします。
-
著作権に触れる可能性がある
クローリング自体は違法行為にはなりません。しかし、クローリングをしたWebサイトなどがクローリングやスクレイピングによる情報収集を禁止している場合、利用規約違反として訴えられる可能性があります。
また、クローリングで情報収集をするWebサイトなどは誰かが作成したものです。そのため、意味のない情報の羅列などを除いてWebサイトは著作物となり、著作物には著作権がともないます。データ解析に利用することについては著作権侵害になりませんが、収集した情報を複製し他人に譲渡した場合などは違法行為とみなされますので注意しましょう。
-
クローリングするWebサイトへ負荷がかかる
Webサイトの情報を閲覧する際は、Webサーバーから該当するWebサイトの情報を引き出す必要があります。クローリングはプログラムのため、実際に人の目にWebサイトが表示されるわけではありません。しかし、Webサイトにアクセスする以上、該当するWebサーバーに負荷をかけていることになります。
実際に、クローリングをおこなっていた男性がWebサイトをダウンさせ、逮捕されるまでに至った「岡崎市中央図書館事件」という事例があります。Webサーバーに過度な負担をかけないためにも、クローリングをする際は十分に調べるようにしましょう。
-
クローリングの活用方法
クローリングの活用方法を3つお伝えします。
-
検索エンジンの作成
プログラミング言語やデータベース、Webサーバーなどの知識があれば、検索エンジンを自作することも可能です。大規模な検索エンジンの開発となると、Yahoo! JAPANが2010年7月にその機能性からGoogleのシステムを利用したように、自社開発をして採算が取れるものではありません。しかし、社内情報や観光名所の情報、求人情報、不動産情報など、何かしらの情報に特化した、ポータルサイト内の検索エンジンとしては活用することができます。
※参考:ならびにYahoo! JAPANからグーグルへのデータ提供について
-
市場調査
クローリングをすることで、SNSでの商品の反応やECサイトでのレビューなどの情報を収集することができます。そのため、自社商品の改善はもとより、同業他社商品との比較なども調査可能です。また、集めた情報は新規事業立ち上げ時のユーザーリサーチにも利用できるので、ユーザー像の想定(ペルソナ)などの事業戦略を立てる資料集めとしても活用できます。
-
営業リストの作成
Web上に公開されている企業の情報に絞ってクローリングをおこなうことで、営業先となる企業のホームページや住所、メールアドレスなどの情報を簡単にリスト化できます。しかし、企業によってはクローリングでの情報収集を利用規約違反にしている可能性もありますので注意しましょう。
-
クローラーの種類
検索エンジンで利用されているクローラーやクローラーツール(スクレイピングツール)を説明します。
-
検索エンジン用クローラー
日本での検索エンジンのシェア率は、Googleが76.97%、Yahoo!JAPANが14.53%と市場の91.5%を占めているため、他の検索エンジンについて意識することは少ないかと思います。しかし、世界には上記以外にも検索エンジンが存在しており、それぞれに利用しているクローラーも異なります。各検索エンジン用のクローラーは以下のものです。
- Googlebot:Google(Yahoo!JAPANもこちらをカスタムして利用)
- Yahoo! Slurp:Yahoo!(日本以外の国のYahoo!で利用)
- Bingbot:Bing(Microsoftの検索エンジン)
- duckduckgo-favicons-bot:DuckDuckGo(アメリカの検索エンジン)
- Baiduspider:Baidu(漢字表記は百度|中国の検索エンジン)
- YandexBot:Yandex(ロシアの検索エンジン)
- Yetibot:NAVER(韓国の検索エンジン)
また、クローラーは「ボット|bot」、「ロボット|robot」、「スパイダー|spider
」などとも呼称されます。
※参考:Search Engine Market Share Japan | Statcounter Global Stats
-
クローラーツール(スクレイピングツール)
クローラーを独自開発しなくてもクローリングをすることができる、「クローリングツール(スクレイピングツール)」やサービスが多数提供されています。
有名なものには、「Octoparse」、「Mozenda」、「Luminati」、「Import.io」などがあり、クローラーを作成する技術がない場合や開発に工数をかけられない場合などに有効活用できます。しかし、有償のものと無償のものがありますので、ランニングコストを考慮したうえで利用するか否かを考える必要があります。
-
クローラーにWebサイトをクローリングさせる方法
上述したように、作成したWebサイトを検索エンジンで表示させるためには、クローラーに認識されなければいけません。しかし、検索エンジンは常にクローリングをおこなっているものの、作成したWebサイトがいつクローリングされるかは分かりません。そのため、作成側からできる対策として、Webサイトの情報を検索エンジンに伝える方法が用意されています。
また、日本の検索エンジンはGoogleとYahoo!JAPANが市場の9割を占め、Yahoo!JAPANもGoogleのツールを利用しています。そのため、クローリング対策=Googleへの対策、といっても過言ではありません。Googleに作成したWebサイトの情報を伝えるには、「Google Search Console」という
Google検索結果でのサイトの掲載順位を監視、管理、改善
するためのツールが必要です。この項で記載する2つの方法は、Google Search ConsoleにWebサイトの情報を伝えるものとなっています。
※参考:Search Console の概要 – Google Support
-
XMLサイトマップを作成・送信する
XMLサイトマップとは、検索エンジンにWebサイトのWebページ構成などの情報を伝えるためのファイルです。大規模なWebサイト、動画・JavaScriptなどを多用したWebサイトやWebページの場合、クローラーがすべての情報を検出できず、正確に把握・評価してくれない可能性があります。そのため、XMLサイトマップを作成・送信し、しっかりと認識されるように促すものです。
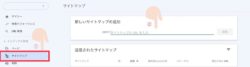
XMLサイトマップをGoogleに送信するためには、Google Search Consoleにログイン後、下記画像にある①「サイトマップ」を選択し、②「新しいサイトマップの追加」にURLを入力する必要があります。
また、Googleの公式サイトでは、XMLサイトマップが必要になるケースもあります。下記の記事では不要なケースについて説明していますので、気になった方はこちらもご参考ください。
※参考:サイトマップの概要 | Google 検索セントラル | ドキュメント
-
インデックスリクエストを送る
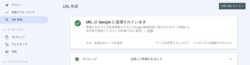
Google Search Consoleにログインし、①「URL検査」を選択、②の場所にWebサイトやWebページのURLを入力すると、Googleの検索結果で該当するWebサイトなどが表示されているか調べることができます。

登録されていた場合は以下が表示されます。
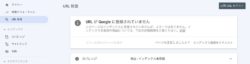
登録されていない場合は以下の表示です。
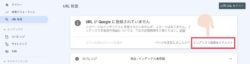
登録されていない場合、表示されたページのまま「インデックス登録をリクエスト」をクリックするとGoogleへ該当URLを登録するよう促すことができます。
Googleに登録されていない場合、Webサイトがクローリングされるまで検索結果に表示されることがありません。新しく作成したWebサイトやWebページはURL検査をおこない、表示されているか確認するようにしましょう。
-
クローリングは抑制することができる
「他のWebページに比べて情報が少なく、Webサイトの評価が下がる可能性があるWebページ」、「会員情報などが掲載されているWebページ」、「投稿の準備をしていて、掲載日をクローリングの情報とできる限り一致させたいWebページ」などがある場合、クローリングを抑制するという対策を講じることができます。
Googleの公式サイトでは、「robots.txt ファイルの作成」、「HTMLページへのメタタグの追加」、「HTTP応答ヘッダーでの指示」でクローラーのアクセスをブロックできると説明されています。設定方法については、下記の記事をご参考ください。
-
クローラー開発に向いているプログラミング言語
RubyとPythonはクローラー開発でよく使われるプログラミング言語です。それぞれの特徴について説明します。
-
Ruby
Rubyは日本人のまつもとゆきひろ氏が開発したオブジェクト指向のスクリプト言語です。文法が簡単で学習環境も整っている、「Ruby on Rails」という作業効率を上げるフレームワークがある、などの理由で人気も高くなっています。
クローラー開発では、「nokogiri」というクローリング(スクレイピング)用のライブラリと、「open-url」というURLへアクセスするための標準ライブラリを利用します。また、Rubyについてはまとめている記事がありますので、こちらもぜひご覧ください。
関連記事:プログラミング言語【Ruby】とは?Rubyの特徴や使用の注意点を解説
-
Python
Pythonも、Rubyと同じように文法が簡単で学習環境が整っている、オブジェクト思考のスクリプト言語です。プログラミング言語として開発できるシステムが多く、近年注目されている人工知能や機械学習、データ解析などにも強いプログラミング言語のため、ここ数年は人気ランキングの上位にランクインし続けています。
Pythonのクローラー開発では、「requests」、「Beautiful Soup」、「Selenium」、「Scrapy」などのライブラリがよく利用されています。これらはそれぞれ「HTML
のダウンロード」、「データ抽出」、「データの保存」の可否や処理速度、学習難易度などが異なりますので、開発したいクローラーに合わせた選択が必要です。
-
まとめ
この記事では、自身がクローリングをする場合と検索エンジンにクローリングされる場合について解説をしました。前者はメリットと注意点について、後者はクローリングされる重要性と対策についてご認識いただければ幸いです。また、自身でクローラーを開発しようとしている方は、検索エンジンで【クローリング(スクレイピング) Ruby(Python)】と検索をすればたくさんの情報が出てきます。ぜひともご確認ください。




